Core Web Vitals: la guida completa a LCP, INP, CLS e metriche di supporto
Guida tecnica e SEO ai Core Web Vitals: LCP, INP, CLS, metriche di supporto come TTFB e FCP, strumenti, soglie ufficiali Google e workflow di ottimizzazione.

Indice dei Contenuti
- Introduzione ai Core Web Vitals: La Rivoluzione della Page Experience
- Perché i Core Web Vitals Contano Davvero: L'Impatto su SEO, UX e Conversion Rate
- Field Data vs. Lab Data: Comprendere la Misurazione dei Web Vitals
- LCP (Largest Contentful Paint): Il Cuore della Velocità Percepita
- INP (Interaction to Next Paint): La Reattività al Centro dell'Attenzione
- CLS (Cumulative Layout Shift): La Stabilità Visiva Senza Compromessi
- Metriche di Supporto per una Diagnosi Approfondita
- Strumenti per Misurare e Analizzare i Core Web Vitals
- Chrome DevTools: La scheda Performance
- Lighthouse e PageSpeed Insights: Auditing on-demand
- Google Search Console: La sezione "Esperienza"
- Chrome UX Report (CrUX) e BigQuery: Dati reali su larga scala
- Web Vitals Extension per Chrome: Monitoraggio in tempo reale
- web-vitals npm library: Monitoraggio programmatico
- Workflow di Ottimizzazione Concreto: Dalla Diagnosi al Monitoring Continuo
- Errori Comuni e Miti da Sfatare sui Core Web Vitals
- Caso Studio 1604lab: Hyvä Magento 2 e Core Web Vitals Eccellenti
- FAQ: Domande Frequenti sui Core Web Vitals
- Quanto sono importanti i Core Web Vitals per la SEO?
- Posso ignorare i Core Web Vitals se ho un sito piccolo?
- È possibile raggiungere un punteggio perfetto su PageSpeed Insights?
- Quanto tempo ci vuole per vedere i miglioramenti dopo l'ottimizzazione?
- I web font influenzano LCP e CLS? Come?
- Che ruolo hanno le CDN nell'ottimizzazione dei Core Web Vitals?
- Fonti Ufficiali e Risorse Utili
- Contattaci per l'ottimizzazione dei tuoi Core Web Vitals
Introduzione ai Core Web Vitals: La Rivoluzione della Page Experience
Nel panorama digitale odierno, l'esperienza utente è diventata un fattore discriminante cruciale per il successo di qualsiasi sito web. Google, sempre più attenta a premiare le piattaforme che offrono non solo contenuti di qualità ma anche un'interazione fluida e priva di attriti, ha introdotto i Core Web Vitals. Questi sono un set di metriche standardizzate, misurabili e incentrate sull'utente, che quantificano aspetti fondamentali dell'esperienza di navigazione di una pagina web: velocità di caricamento, interattività e stabilità visiva. Comprendere e ottimizzare i Core Web Vitals non è più un'opzione, ma una necessità strategica per chiunque desideri eccellere online.
Il punto di svolta per l'importanza dei Core Web Vitals è arrivato con l'annuncio e la successiva implementazione, a partire dal 2021, del cosiddetto Page Experience Update. Questa aggiornamento algoritmico ha elevato i Core Web Vitals a veri e propri fattori di ranking, affiancandosi ad altri segnali di esperienza utente già consolidati come l'adattabilità mobile, la sicurezza HTTPS e l'assenza di interstitial intrusivi. Google ha così chiaramente segnalato che un sito web percepito come lento, instabile o poco reattivo, anche se ricco di contenuti pertinenti, potrebbe vedere penalizzata la sua visibilità nei risultati di ricerca.
Una delle evoluzioni più recenti e significative in questo ambito è l'introduzione dell'INP (Interaction to Next Paint). A partire da marzo 2024, INP ha ufficialmente sostituito il First Input Delay (FID) come metrica principale per la reattività. Questa transizione riflette la volontà di Google di misurare in modo più completo e accurato l'intera latenza di risposta alle interazioni dell'utente, andando oltre la semplice prima impressione. INP cattura l'intervallo di tempo dal momento in cui un utente interagisce con una pagina (clic, tap, tastiera) fino a quando il browser non è in grado di dipingere il frame visivo successivo che riflette il risultato di quella interazione. Questo lo rende un indicatore molto più robusto e rappresentativo dell'esperienza utente rispetto al solo FID.
In sintesi, i Core Web Vitals non sono solo un insieme di numeri tecnici da monitorare; sono una bussola che guida gli sviluppatori e i proprietari di siti web verso la creazione di esperienze digitali superiori. Ignorarli significa rischiare di compromettere la visibilità organica, la user satisfaction e, in ultima analisi, il successo commerciale. Questo articolo si propone di esplorare in profondità ciascuna di queste metriche, fornendo le conoscenze tecniche e le strategie pratiche per ottimizzare il tuo sito e garantirgli una posizione di rilievo nel panorama competitivo del web.
Perché i Core Web Vitals Contano Davvero: L'Impatto su SEO, UX e Conversion Rate
L'importanza dei Core Web Vitals va ben oltre la semplice adesione alle linee guida di Google. Essi rappresentano un ponte diretto tra le prestazioni tecniche di un sito e il suo impatto sul business, influenzando tre pilastri fondamentali: la SEO, l'esperienza utente (UX) e il tasso di conversione (CRO).
SEO: Il Binomio Indissolubile con il Mobile-First
L'algoritmo di Google ha ormai da anni adottato un approccio mobile-first indexing. Ciò significa che il motore di ricerca valuta prevalentemente la versione mobile del tuo sito per il ranking. In questo contesto, i Core Web Vitals assumono un'importanza capitale: un sito lento o poco reattivo su dispositivi mobili, spesso con connessioni meno stabili o hardware meno performante, avrà maggiori difficoltà a rankare rispetto a un concorrente ottimizzato. Google lo ha dichiarato esplicitamente: i Core Web Vitals sono segnali di ranking. Sebbene non siano l'unico fattore – il contenuto di qualità rimane primario – in uno scenario competitivo, possono essere l'ago della bilancia. Migliorare questi segnali può fare la differenza tra posizionarsi in prima pagina o nelle retrovie, specialmente per parole chiave di media e alta concorrenza dove la qualità tecnica del sito può essere un fattore distintivo.
Esperienza Utente: Il Cuore della Soddisfazione Clienti
Un'esperienza utente positiva è la base per fidelizzare i visitatori. Al contrario, un'esperienza negativa li allontana rapidamente. I Core Web Vitals quantificano direttamente aspetti percepibili dall'utente:
- LCP (Largest Contentful Paint) risponde alla domanda "Quanto tempo ci vuole prima che la pagina sia visibilmente utile?". Se l'elemento principale tarda a comparire, l'utente percepisce la pagina come lenta.
- INP (Interaction to Next Paint) valuta "Quanto tempo impiega la pagina a rispondere alle mie interazioni?". Ritardi nelle risposte a clic o digitazioni generano frustrazione e sensazione di inefficienza.
- CLS (Cumulative Layout Shift) si concentra su "La pagina si muove in modo inaspettato mentre interagisco?". I salti di layout sono fastidiosi e possono portare a clic errati, minando la fiducia e l'usabilità.
Quando questi indicatori sono negativi, la frustrazione degli utenti cresce, i tassi di rimbalzo aumentano e la volontà di tornare sul sito diminuisce. Un'esperienza fluida e piacevole, al contrario, incoraggia l'esplorazione, la permanenza e la navigazione tra le diverse sezioni del sito.
Conversion Rate: Dati Reali sull'Impatto Economico
L'impatto dei Core Web Vitals si traduce direttamente in benefici economici per le aziende. Numerosi studi settoriali hanno dimostrato una correlazione diretta tra prestazioni del sito e tassi di conversione:
- Akamai e Deloitte: Uno studio di Akamai ha rivelato che un ritardo di appena 100 millisecondi nel tempo di caricamento di una pagina può ridurre i tassi di conversione del 7%. Deloitte, in un rapporto intitolato "Milliseconds Make Millions", ha evidenziato come miglioramenti minimi nella velocità possano generare aumenti significativi nei ricavi per le grandi aziende e-commerce. Ad esempio, per un sito che genera 10 milioni di dollari al giorno, un miglioramento di 0.1 secondi nel tempo di caricamento può tradursi in un guadagno di 1.2 milioni di dollari annuali.
- Google Case Studies: Google stessa ha pubblicato numerosi case study che dimostrano l'impatto positivo dell'ottimizzazione dei Core Web Vitals. Ad esempio, siti come Pinterest e Vodafone hanno registrato aumenti delle conversioni, del coinvolgimento degli utenti e riduzioni dei tassi di abbandono dopo aver migliorato le proprie metriche. Pinterest ha riportato un aumento del 15% nelle iscrizioni e un miglioramento del 15% nel traffico organico dopo aver ottimizzato il loro LCP. Vodafone ha visto un 8% di aumento nelle vendite e un 11% di miglioramento nel tasso di conversione Lead-to-Visit.
- Esperimenti A/B: Tantissime aziende conducono esperimenti A/B dimostrando come anche piccoli incrementi nella velocità di pagina portino a significative migliorie nel tasso di aggiunta al carrello, nel completamento di form e negli acquisti. Ad esempio, Walmart ha visto un aumento delle conversioni del 2% per ogni secondo di miglioramento nel caricamento della pagina.
Questi dati non sono aneddotici; sono la prova tangibile che investire nell'ottimizzazione delle prestazioni del sito è un investimento diretto nella crescita del business. Un sito performante non solo attira più traffico dai motori di ricerca, ma converte anche più efficacemente quel traffico in clienti, generando un circolo virtuoso di successo. Pertanto, i Core Web Vitals non sono semplicemente un "compito da SEO", ma una metrica strategica che richiede l'attenzione di chiunque sia coinvolto nella gestione e nello sviluppo di un'attività online.
Field Data vs. Lab Data: Comprendere la Misurazione dei Web Vitals
Per affrontare efficacemente l'ottimizzazione dei Core Web Vitals, è fondamentale comprendere la distinzione tra "field data" (dati sul campo) e "lab data" (dati di laboratorio). Questa differenza è cruciale perché i due tipi di dati vengono raccolti ed elaborati in contesti diversi e forniscono prospettive complementari sulle prestazioni del tuo sito.
Field Data: Misurare l'Esperienza Reale degli Utenti (CrUX, RUM)
I field data sono dati di prestazioni raccolti da utenti reali che navigano sul tuo sito. Sono il "mondo reale": tengono conto di una miriade di fattori variabili come il tipo di dispositivo (desktop, mobile, tablet), la velocità della connessione di rete (4G, 5G, Wi-Fi), la posizione geografica degli utenti, i software in esecuzione background e persino le condizioni meteorologiche (che possono influenzare le connessioni satellitari). Questi dati sono incredibilmente preziosi perché riflettono esattamente come gli utenti percepiscono il tuo sito e sono i dati che Google utilizza per il ranking.
- Chrome User Experience Report (CrUX): Questa è la fonte autoritativa per i field data di Google. Il CrUX raccoglie dati anonimizzati da utenti Chrome reali che hanno acconsentito alla sincronizzazione della cronologia di navigazione e all'invio di statistiche sull'utilizzo. Questi dati vengono aggregati e resi disponibili pubblicamente, alimentando strumenti come PageSpeed Insights e Google Search Console. Il CrUX fornisce metriche per LCP, INP e CLS basate su un periodo di 28 giorni.
- Real User Monitoring (RUM): Un'altra forma di field data è il RUM, che prevede l'integrazione di script JavaScript direttamente nel codice del tuo sito. Questi script raccolgono dati sulle prestazioni da ogni singola visita dell'utente e li inviano a un servizio di monitoraggio di terze parti (es. New Relic, Dynatrace, o soluzioni self-hosted come la web-vitals JavaScript library di Google, che discuteremo più avanti). Il RUM offre una granularità molto maggiore rispetto al CrUX, permettendoti di segmentare i dati per browser, dispositivo, area geografica o persino utente autenticato, fornendo un'analisi molto più dettagliata dei problemi specifici.
Il Percentile 75°: Quando Google analizza i field data, si concentra sul 75° percentile. Ciò significa che per una determinata metrica (LCP, INP, CLS), il punteggio "pass" o "good" viene assegnato se almeno il 75% di tutte le visualizzazioni di pagina di un sito rientrano nelle soglie considerate "buone". Questa scelta è deliberata: non basta che il tuo sito sia veloce per la maggior parte degli utenti, ma deve esserlo anche per una porzione significativa degli utenti con condizioni di rete o dispositivi meno ideali. È qui che la sfida diventa più complessa e realistica.
Lab Data: Diagnosi Controllata (Lighthouse, PageSpeed Insights)
I lab data, al contrario, sono dati raccolti in un ambiente controllato e simulato. Questi dati vengono generati utilizzando strumenti automatizzati che emulano il caricamento di una pagina in condizioni predefinite (es. una connessione mobile 4G throttled, un dispositivo di fascia media). I lab data sono riproducibili e ideali per il debugging e l'identificazione delle cause alla base dei problemi di performance.
- Lighthouse: Integrato direttamente in Chrome DevTools e accessibile anche come CLI tool, Lighthouse esegue un audit completo di una pagina in un ambiente di laboratorio. Simula un caricamento fresco della pagina e fornisce un punteggio per le prestazioni, insieme a suggerimenti diagnostici specifici. È eccellente per identificare i "colli di bottiglia" tecnici.
- PageSpeed Insights (PSI): Questo strumento di Google combina sia field data (dal CrUX) che lab data (da Lighthouse). Quando inserisci un URL, PSI ti mostrerà i dati reali per quella pagina (se disponibili nel CrUX) e contemporaneamente eseguirà un'analisi di Lighthouse sul momento, offrendo così una doppia prospettiva. I suggerimenti di ottimizzazione forniti da PSI sono basati sull'analisi Lighthouse.
- web-vitals JS library (modalità lab): Sebbene principalmente pensata per il RUM, la libreria
web-vitalspuò essere usata con strumenti di testing interni per generare dati di laboratorio simulati.
Sinergia tra Field e Lab Data: Un Approccio Integrato
È cruciale comprendere che field data e lab data non sono in competizione, ma si completano a vicenda:
- I Field Data ti dicono quali Core Web Vitals sono problematici per i tuoi utenti reali e quanto grave è il problema (es. "Il mio LCP è insufficiente per il 30% dei miei utenti mobile"). Sono la "verità" per Google.
- I Lab Data ti aiutano a capire perché quei Core Web Vitals sono problematici e come risolverli (es. "Il mio LCP è elevato perché l'immagine principale non è ottimizzata e il server risponde lentamente").
Un workflow di ottimizzazione ideale prevede di iniziare con l'analisi dei field data (Search Console, PSI) per identificare le pagine problematiche, e poi utilizzare i lab data (Chrome DevTools, Lighthouse) per diagnosticare e testare le soluzioni. Dopo aver implementato i fix, si monitorano nuovamente i field data per verificare l'impatto delle modifiche sull'esperienza utente reale. Senza questa combinazione, si rischia di ottimizzare per metriche di laboratorio che non riflettono l'esperienza utente effettiva, o di essere incoscienti delle cause profonde dei problemi rilevati dagli utenti reali.
LCP (Largest Contentful Paint): Il Cuore della Velocità Percepita
Il Largest Contentful Paint (LCP) è una delle tre metriche fondamentali dei Core Web Vitals e probabilmente la più tangibile in termini di "velocità percepita". Misura il tempo impiegato dal browser per renderizzare il contenuto principale o più significativo visibile all'utente all'interno della viewport. È un indicatore chiave di quanto rapidamente un utente possa considerare una pagina "utile" o "caricata".
Cosa misura il LCP e perché è fondamentale
LCP misura il tempo dal momento in cui l'utente avvia il caricamento della pagina fino a quando il browser non ha renderizzato il blocco di testo più grande o l'immagine principale all'interno dell'area visibile (viewport) della pagina. Questo "elemento più grande" è quello che Google considera il contenuto più significativo per l'utente, e vederlo apparire rapidamente è essenziale per una buona prima impressione.
Perché è così fondamentale? Perché la percezione della velocità è tanto importante quanto la velocità effettiva. Se un utente vede rapidamente il contenuto principale, anche se il resto della pagina non è ancora completamente interattivo, percepisce il sito come veloce e reattivo. Ritardi nell'LCP portano a frustrazione e abbandono precoce della pagina, indipendentemente dalla velocità complessiva del sito una volta caricato.
Soglie LCP e interpretazione dei risultati
Le soglie stabilite da Google per un LCP "buono" sono:
- Buono: LCP inferiore a 2.5 secondi
- Migliorabile: LCP tra 2.5 e 4.0 secondi
- Insufficiente: LCP superiore a 4.0 secondi
Queste soglie, come menzionato in precedenza, devono essere raggiunte al 75° percentile delle visualizzazioni di pagina. Un LCP di 2.5 secondi significa che per almeno il 75% delle visite, l'elemento più grande della viewport è apparso entro 2.5 secondi. Superare queste soglie significa che una porzione significativa dei tuoi utenti sta vivendo un'esperienza di caricamento subottimale, con potenziali impatti negativi su ranking e conversioni.
Elementi candidati LCP: cosa cercare
Non tutti gli elementi della pagina possono essere l'LCP. Google identifica i seguenti tipi di elementi come candidati principali per diventare l'Largest Contentful Paint:
- Elementi
<img>all'interno di un tag<img>. - Elementi
<image>all'interno di un<svg>. - Elementi
<video>con attributopostero con un elemento<source>associato, da cui viene estratta l'immagine di anteprima. - Elementi con un'immagine di sfondo caricata tramite la funzione
url()in CSS (non il classico sfondo SVG o gradiente). - Blocchi di testo a livello di blocco (es.
<p>,<h1>,<li>,<div>, ecc.) che contengono nodi di testo figli o elementi inline-level.
È fondamentale identificare quale sia l'LCP della tua pagina (spesso mostrato in Lighthouse o Chrome DevTools) per poter concentrare gli sforzi di ottimizzazione su quell'elemento specifico e sulle risorse che lo rendono visibile.
Cause comuni di un LCP elevato
Un LCP elevato può essere attribuito a diverse problematiche, spesso interconnesse:
- Lento TTFB (Time to First Byte): Questo è il tempo che intercorre dalla richiesta iniziale della pagina fino alla ricezione del primo byte di risposta dal server. Un TTFB lento può essere dovuto a un hosting scadente, un server sovraccarico, una logica di backend complessa o query al database inefficienti. Se il server impiega molto tempo a rispondere, il browser non può nemmeno iniziare a elaborare la pagina.
- Risorse che bloccano il rendering (Render-Blocking Resources): Script JavaScript e fogli di stile CSS caricati in modo sincrono nell'
<head>del documento possono bloccare il rendering della pagina. Il browser deve scaricarli, analizzarli ed eseguirli prima di poter visualizzare qualsiasi cosa, compreso l'LCP. - Tempi di caricamento delle risorse prolungati: Se l'elemento LCP è un'immagine o un video, il tempo necessario per scaricare e renderizzare tale risorsa è critico. Questo è influenzato dalle dimensioni del file, dal formato, dalla compressione e dalla priorità di caricamento.
- Rendering client-side: Le applicazioni React, Angular, Vue (e altri framework JS) che si basano pesantemente sul rendering client-side possono ritardare l'LCP. Il browser deve scaricare, analizzare ed eseguire una grande quantità di JavaScript prima che il contenuto effettivo appaia nella DOM. Questo può portare a un LCP tardivo anche se il TTFB è buono.
- Font web non ottimizzati: Anche i font web possono bloccare il rendering o causare ritardi. Se l'LCP è un blocco di testo che utilizza un font web, il browser potrebbe dover attendere il download del font prima di poter visualizzare il testo.
- Lazy loading dell'elemento LCP: È paradossale, ma un errore comune è applicare il lazy loading (
loading="lazy") all'immagine o all'elemento principale che si trova above-the-fold (visibile senza scroll). Questo impedisce al browser di dare priorità al caricamento di quell'elemento, ritardandone la comparsa. Solo gli elementi al di sotto dell'area visibile dovrebbero essere caricati in modo differito.
Strategie di ottimizzazione per il LCP
L'ottimizzazione dell'LCP richiede un approccio a più livelli, intervenendo sia sul lato server che sul lato client. Ecco le strategie più efficaci:
- Ottimizzare il TTFB:
- Hosting di qualità: Scegli provider di hosting performanti, preferibilmente con server geograficamente vicini alla tua audience.
- CDN (Content Delivery Network): Utilizza una CDN per distribuire i tuoi asset statici (immagini, CSS, JS) su server vicini all'utente, riducendo la latenza. Molte CDN offrono anche ottimizzazioni delle immagini e del caching.
- Caching server-side: Implementa una strategia di caching aggressiva a livello di server (Varnish, Redis, Nginx FastCGI Cache) per servire pagine statiche o quasi statiche più velocemente.
- Ottimizzazione backend: Riduci i tempi di esecuzione delle query al database, ottimizza il codice del server-side (PHP, Python, Node.js) e usa algoritmi efficienti.
- Preconnessione a domini di terze parti: Se il tuo LCP dipende da risorse hostate su altri domini (es. CDN, font providers, analytics), usa
<link rel="preconnect">per stabilire una connessione anticipata.
- Rimuovere risorse che bloccano il rendering:
- CSS:
- Critical CSS: Estrai il CSS necessario per renderizzare il contenuto above-the-fold e inlinelo direttamente nell'HTML (
<style>tag). - Async CSS: Carica il CSS non critico in modo asincrono usando
<link rel="preload" href="style.css" as="style" onload="this.onload=null;this.rel='stylesheet'"> <noscript><link rel="stylesheet" href="style.css"></noscript>. - Minificazione e compressione: Riduci le dimensioni dei file CSS.
- Critical CSS: Estrai il CSS necessario per renderizzare il contenuto above-the-fold e inlinelo direttamente nell'HTML (
- JavaScript:
- Differ defer e async: Carica script JavaScript non critici con gli attributi
deferoasyncper impedirne il blocco del parser HTML. - Code splitting: Suddividi il JavaScript in bundle più piccoli e caricali solo quando necessario (lazy loading di moduli).
- Minificazione, compressione e rimozione del codice inutilizzato: Simile al CSS, riduci le dimensioni e il codice superfluo.
- Differ defer e async: Carica script JavaScript non critici con gli attributi
- CSS:
- Ottimizzare i tempi di caricamento delle risorse:
- Immagini:
- Dimensioni responsive: Utilizza l'attributo
srcsete l'elemento<picture>per servire immagini di dimensioni appropriate al dispositivo dell'utente. - Formati moderni: Usa formati come WebP o AVIF che offrono una migliore compressione rispetto a JPEG o PNG.
- Compressione: Comprimi le immagini senza perdita eccessiva di qualità.
- preload e fetchpriority: Se l'elemento LCP è un'immagine, segnala al browser di caricarla con priorità. Usa
<link rel="preload" href="hero.jpg" as="image">e/o l'attributofetchpriority="high"sull'elemento<img>. - Evita il lazy loading sull'LCP: Assicurati che l'immagine LCP (above-the-fold) non abbia l'attributo
loading="lazy".
- Dimensioni responsive: Utilizza l'attributo
- Video: Ottimizza i formati, la compressione e assicurati che l'attributo
postersia un'immagine leggera e ottimizzata. - Web Font:
font-display: optionaloswap: Utilizza queste proprietà CSS per evitare il "flash of unstyled text" (FOUT) o il "flash of invisible text" (FOIT) e per consentire al browser di renderizzare il testo usando un font di sistema mentre il font web viene caricato.- Preload dei font: Se il font è critico, precaricalo usando
<link rel="preload" href="font.woff2" as="font" type="font/woff2" crossorigin>. - Subsetting dei font: Includi solo i caratteri e i pesi necessari.
- Immagini:
- Server-Side Rendering (SSR) o Static Site Generation (SSG): Per siti basati su framework JavaScript, l'implementazione di SSR o SSG può drasticamente migliorare l'LCP, servendo una versione pre-renderizzata dell'HTML contenente il contenuto principale.
Esempi pratici di ottimizzazione LCP
Esempio 1: Precaricare un'immagine LCP cruciale
Supponiamo che l'immagine di header del tuo sito sia l'elemento LCP. Senza ottimizzazione, il browser la scopre solo dopo aver analizzato parte del DOM.
<!-- HTML senza ottimizzazione LCP -->
<div class="hero">
<img src="hero-image.jpg" alt="Descrizione">
</div>Per dare priorità massima, puoi usare preload e fetchpriority="high":
<!-- Nel <head> per precaricare il più presto possibile -->
<link rel="preload" href="hero-image.jpg" as="image">
<!-- Nel <body> sull'immagine -->
<div class="hero">
<img src="hero-image.jpg" alt="Descrizione" width="1200" height="600" fetchpriority="high">
</div>Assicurati inoltre di aggiungere gli attributi width e height per evitare CLS e che hero-image.jpg sia ottimizzata (WebP/AVIF, compressa, responsive con srcset se serve).
Esempio 2: Ottimizzazione Critical CSS
Considera uno scenario in cui hai un CSS pesante che blocca il rendering.
<!-- CSS che blocca il rendering -->
<link rel="stylesheet" href="/assets/css/main.css">
...
<h1>Welcome</h1>Per ottimizzare, estrai il CSS essenziale per l'header e inlinelo, poi carica il resto in modo asincrono:
<head>
<style>
/* Critical CSS per l'above-the-fold */
body { font-family: sans-serif; }
h1 { font-size: 2em; color: #333; }
.header { background-color: #f0f0f0; padding: 20px; }
</style>
<link rel="preload" href="/assets/css/main.css" as="style" onload="this.onload=null;this.rel='stylesheet'">
<noscript><link rel="stylesheet" href="/assets/css/main.css"></noscript>
</head>
<body>
<header class="header">
<h1>Welcome</h1>
</header>
</body>Questo permette al browser di renderizzare l'<h1> e l'<header> immediatamente, mentre il resto del CSS viene caricato in background.
Esempio 3: Differire JavaScript non essenziale
Se hai script JavaScript che non sono necessari per il caricamento iniziale del contenuto above-the-fold, caricali con defer o async.
<!-- Script che blocca il rendering -->
<script src="analytics.js"></script>
<script src="third-party-widget.js"></script>
</head>Ottimizzato:
<!-- Script che non blocca il rendering -->
<script src="analytics.js" defer></script>
<script src="third-party-widget.js" async></script>
</head>defer garantisce che lo script venga eseguito dopo che il documento HTML è stato completamente analizzato, mantenendo l'ordine di esecuzione relativo degli script con defer. async consente l'esecuzione non bloccante e asincrona ma non garantisce l'ordine.
L'LCP è una metrica complessa ma estremamente gratificante da ottimizzare. Concentrandosi sulla riduzione dei tempi di risposta del server, sulla minimizzazione delle risorse che bloccano il rendering e sull'ottimizzazione del caricamento dell'elemento LCP, si possono ottenere miglioramenti significativi nella velocità percepita e nell'esperienza utente.
INP (Interaction to Next Paint): La Reattività al Centro dell'Attenzione
L'Interaction to Next Paint (INP) è una metrica relativamente nuova che ha assunto un ruolo centrale nei Core Web Vitals, sostituendo il First Input Delay (FID) a partire da marzo 2024. Questa transizione riflette l'evoluzione di Google verso una misurazione più olistica e rappresentativa della reattività di una pagina web alle interazioni dell'utente. Mentre FID misurava solo il ritardo della prima interazione, INP abbraccia l'intera durata della sessione di un utente, identificando il peggiore dei ritardi di interazione e fornendo una visione più accurata dell'esperienza di reattività.
Definizione e significato di INP
INP misura la latenza di tutte le interazioni che avvengono su una pagina durante la sua intera durata sulla viewport dell'utente. Registra il tempo che intercorre dall'input dell'utente (un clic, un tap su un touch screen, la pressione di un tasto) fino al momento in cui il browser è in grado di dipingere il frame visivo successivo che riflette il feedback dell'interazione. In altre parole, è il tempo che passa tra l'azione dell'utente e la risposta visiva che quella azione produce sulla pagina.
La metrica si focalizza sulla singola interazione più lenta ("longest interaction") durante la vita della pagina (escludendo alcune interazioni di background come lo scrolling) e riporta quel valore. Questo è fondamentale per catturare i momenti in cui la pagina "si blocca" o sembra non rispondere, momenti che generano profonda frustrazione negli utenti.
L'INP è composto da tre fasi principali:
- Input Delay: Il tempo che intercorre tra l'inizio dell'interazione dell'utente e il momento in cui i callback dell'evento effettivo iniziano ad essere eseguiti. Questo ritardo spesso si verifica perché il thread principale è occupato a eseguire altri task.
- Processing Time: Il tempo necessario per eseguire i callback dell'evento associati all'interazione, es. l'esecuzione di JavaScript che aggiorna l'UI.
- Presentation Delay: Il tempo impiegato dal browser per dipingere il frame successivo che riflette visivamente l'aggiornamento dell'UI causato dall'interazione. Questo include calcolo dello stile, layout, pittura e composizione.
È importante notare che l'INP non include il tempo necessario per il recupero delle risorse (es. fetching di dati da un'API), ma si concentra sulla reattività visiva della pagina dopo che l'input è stato ricevuto.
Soglie INP e la loro importanza
Le soglie stabilite da Google per l'INP sono:
- Buono: INP inferiore a 200 millisecondi
- Migliorabile: INP tra 200 e 500 millisecondi
- Insufficiente: INP superiore a 500 millisecondi
Anche per l'INP, come per l'LCP e il CLS, si applica il 75° percentile. Ciò significa che almeno il 75% delle interazioni registrate dagli utenti reali devono avvenire entro 200ms per considerare la pagina "buona" in termini di reattività. Se anche solo una piccola percentuale di interazioni è costantemente lenta, l'esperienza complessiva dell'utente ne risente negativamente. Un INP elevato indica che gli utenti percepiscono ritardi significativi tra le loro azioni e le risposte della pagina, portando a frustrazione. Questo è particolarmente vero per le applicazioni web interattive, SPA o siti con molti elementi di UI dinamici.
Cause di un INP elevato: capire i colli di bottiglia
Un INP elevato è quasi sempre sintomo di un thread principale del browser sovraccarico o bloccato, il che impedisce al browser di rispondere prontamente agli input dell'utente. Ecco le cause più comuni:
- Long Tasks (Task Lenti): Operazioni JavaScript che richiedono molto tempo per essere eseguite sul thread principale del browser. Questi task possono ritardare l'elaborazione degli input dell'utente, causando l'input delay e il processing time dell'INP. Esempi includono l'esecuzione di script pesanti, la manipolazione complessa del DOM, il calcolo di animazioni o l'inizializzazione di grandi librerie.
- JavaScript pesante o non ottimizzato:
- Parsing e compilazione eccessiva: Un grande volume di JavaScript deve essere scaricato, analizzato, compilato ed eseguito. Questo processo consuma risorse del thread principale.
- Esecuzione ininterrotta: Se il JavaScript viene eseguito in blocchi lunghi senza concedere tempo al browser di gestire altri compiti (come l'elaborazione degli input), il thread principale si blocca.
- Polling o listener eventi inefficienti: Logiche che controllano o aggiornano frequentemente l'UI senza necessità, o listener eventi che eseguono operazioni troppo complesse.
- Hydration di framework JavaScript (React, Next.js, Vue): Nel caso di Server-Side Rendering (SSR) o Static Site Generation (SSG) con successivo hydration client-side, il processo in cui il JavaScript riattiva la pagina pre-renderizzata può essere molto costoso. Durante l'hydration, il browser deve riconnettere i listener di eventi, ricostruire lo stato e rendere interattivi i componenti, bloccando spesso il thread principale per periodi prolungati.
- Codice di terze parti: Script di terze parti (analytics, advertising, widget di social media, chat, ecc.) sono una causa frequente di problemi di INP. Possono eseguire task lenti, bloccare il thread principale, caricare risorse aggiuntive o iniettare DOM elementi che causano layout shift e re-rendering costosi.
- Eccessivo lavoro di layout e rendering: Anche dopo che il JavaScript dell'evento è stato eseguito, il browser deve ricalcolare gli stili, il layout e poi dipingere i pixel sullo schermo. Se questa fase è eccessivamente costosa (es. manipolazioni DOM complesse, animazioni costose in CSS o JS, invalidazione di stili su molti elementi), può contribuire al presentation delay dell'INP.
Tecniche per ottimizzare l'INP e migliorare la reattività
L'ottimizzazione dell'INP richiede la riduzione del lavoro sul thread principale del browser e la garanzia che gli input dell'utente possano essere elaborati rapidamente. Ecco le strategie chiave:
- Decomporre i Long Tasks (Yielding to Main Thread):
- Suddividere il lavoro: Invece di eseguire un'operazione JavaScript lunga in un unico blocco, suddividila in task più piccoli che possono essere eseguiti in sequenza, consentendo al browser di tornare al thread principale tra un task e l'altro.
scheduler.yield()(proposta): Questa API, attualmente in fase di proposta e sperimentazione, è pensata per consentire agli sviluppatori di indicare al browser che un pezzo di lavoro può essere interrotto e ripreso più tardi, dando la precedenza a eventi critici come gli input utente.setTimeout()con zero delay: Un pattern più rudimentale ma efficace per "cedere" il thread è avvolgere parti di codice insetTimeout(..., 0). Questo sposta il task alla fine della coda dei messaggi della UI, permettendo al browser di elaborare eventi in attesa.
- Utilizzare i Web Workers: I Web Workers consentono di eseguire script JavaScript in background su un thread separato dal thread principale. Questo è ideale per eseguire calcoli complessi, elaborazione dati o altre operazioni costose senza bloccare l'interfaccia utente.
- Code Splitting e Lazy Loading di JavaScript:
- Suddividi il tuo bundle JavaScript in blocchi più piccoli e caricali solo quando sono effettivamente necessari. Ad esempio, carica il codice per un modale solo quando l'utente clicca sul pulsante che lo apre.
- Usa
import()dinamici per moduli JavaScript e funzionalità che non sono essenziali per il caricamento iniziale e l'interattività di base.
- Rimuovere JavaScript non essenziale: Identifica e rimuovi tutto il codice JavaScript che non è strettamente necessario o che può essere differito senza impattare la funzionalità cruciale.
- Ottimizzazione dell'Hydration (per SPAs/framework):
- Progressive Hydration: Invece di idratare l'intera applicazione in una volta, idratare i componenti in modo incrementale, dando priorità a quelli critici.
- Partial Hydration: Idratare solo i componenti che richiedono interattività, lasciando il resto come HTML statico.
- Resumability: Tecnologie come Qwik stanno esplorando approcci in cui il JavaScript non ha bisogno di "reidratare" lo stato dopo il rendering server-side, migliorando la reattività iniziale.
- Ottimizzare gli Event Handlers:
- Debouncing e Throttling: Per eventi che si attivano frequentemente (es.
resize,scroll,mousemove,input), usa debouncing o throttling per limitare la frequenza di esecuzione dei callback. - Evita operazioni costose nei callback: Gli handler degli eventi dovrebbero eseguire il minor lavoro possibile. Se un'operazione è complessa, differiscila usando
setTimeout(..., 0)o un Web Worker. - Delegazione degli eventi: Invece di allegare un listener a ogni singolo elemento, usa la delegazione degli eventi per allegare un singolo listener a un elemento genitore più elevato.
- Debouncing e Throttling: Per eventi che si attivano frequentemente (es.
- Minimizzare il lavoro di layout e styling:
- Evita forzare layout sincronizzati (es. leggere proprietà di layout e poi scriverle ripetutamente).
- Usa CSS il più possibile, preferendo le trasformazioni CSS (
transform,opacity) alle manipolazioni di proprietà che attivano layout e paint costosi. - Isola le aree da aggiornare con
containCSS.
- Ottimizzare le terze parti: Carica script di terze parti con
deferoasync. Se possibile, ritarda il loro caricamento fino a che la pagina non è completamente interattiva o fino a che l'utente non scrolla. Considera l'hosting di risorse di terze parti sul tuo dominio per un maggiore controllo.
Esempi di codice per l'ottimizzazione INP
Esempio 1: Cedere il thread principale con setTimeout
Supponiamo un calcolo pesante che blocca l'UI:
// Codice che blocca l'UI
document.getElementById('myButton').addEventListener('click', () => {
let result = 0;
for (let i = 0; i < 100000000; i++) {
result += Math.sqrt(i);
}
document.getElementById('output').textContent = `Risultato: ${result}`;
});Ottimizzato per cedere il thread:
// Codice ottimizzato con setTimeout
document.getElementById('myButton').addEventListener('click', () => {
// Inizia un task asincrono
setTimeout(() => {
let result = 0;
for (let i = 0; i < 100000000; i++) {
result += Math.sqrt(i);
}
document.getElementById('output').textContent = `Risultato: ${result}`;
}, 0); // Cede il thread principale per consentire altre operazioniQuesto permette al browser di processare altri eventi (come altri clic o animazioni) prima di eseguire il calcolo pesante, migliorando la reattività percepita.
Esempio 2: Utilizzare un Web Worker per calcoli pesanti
File worker.js:
// worker.js
self.onmessage = (event) => {
const data = event.data;
let result = 0;
for (let i = 0; i < data.iterations; i++) {
result += Math.sqrt(i);
}
self.postMessage(result);
};Nel file principale main.js:
// main.js
const myWorker = new Worker('worker.js');
document.getElementById('myButton').addEventListener('click', () => {
console.log('Calcolo avviato...');
myWorker.postMessage({ iterations: 100000000 }); // Invia data al worker
myWorker.onmessage = (event) => {
document.getElementById('output').textContent = `Risultato: ${event.data}`;
console.log('Calcolo completato dal worker.');
};
});L'UI rimane completamente reattiva durante l'esecuzione del calcolo pesante in background.
Esempio 3: Debounce per eventi frequenti
Per un campo di ricerca con auto-completamento che effettua chiamate API:
// Funzione debounce
function debounce(func, delay) {
let timeout;
return function(...args) {
const context = this;
clearTimeout(timeout);
timeout = setTimeout(() => func.apply(context, args), delay);
};
}
const searchInput = document.getElementById('search');
const fetchSuggestions = (query) => {
console.log(`Cercando suggerimenti per: ${query}`);
// Qui andrebbe la chiamata API
};
// Listener senza debounce
// searchInput.addEventListener('input', (e) => fetchSuggestions(e.target.value));
// Listener con debounce
const debouncedFetchSuggestions = debounce(fetchSuggestions, 300);
searchInput.addEventListener('input', (e) => debouncedFetchSuggestions(e.target.value));Questo evita di chiamare fetchSuggestions ad ogni digitazione, riducendo il carico e migliorando la reattività percepita.
L'ottimizzazione dell'INP è un compito complesso che mira a rendere il tuo sito reattivo e piacevole da usare, eliminando i "punti morti" dove l'utente si sente ignorato. Richiede una profonda comprensione del funzionamento del thread principale del browser e una pianificazione attenta di come il JavaScript viene caricato ed eseguito.
CLS (Cumulative Layout Shift): La Stabilità Visiva Senza Compromessi
Il Cumulative Layout Shift (CLS) è la terza metrica fondamentale dei Core Web Vitals e si concentra sulla stabilità visiva della pagina. Misura la quantità di spostamento inaspettato degli elementi del layout che si verifica sulla pagina mentre essa si sta caricando e durante la navigazione dell'utente. Un CLS elevato è una delle esperienze utente più frustranti, causando errori di clic, perdita di contesto e una generale sensazione di instabilità e scarsa qualità del sito.
Definizione e misurazione del CLS
Il CLS quantifica il "layout shift" inaspettato. Un layout shift si verifica quando un elemento visibile cambia la sua posizione di partenza tra due frame renderizzati. Non tutti i layout shift sono negativi; quelli che avvengono in risposta a un'interazione utente (es. apertura di un menu di navigazione) sono previsti e non contribuiscono al CLS. Il CLS si applica solo agli spostamenti non attesi dall'utente.
Il punteggio CLS viene calcolato moltiplicando due fattori:
- Impact Fraction: Misura quanto spazio della viewport è stato influenzato da un layout shift. È l'unione dell'area visibile degli elementi instabili prima e dopo lo spostamento, divisa per l'area totale della viewport. Ad esempio, se un elemento si sposta e occupa il 50% della viewport prima e dopo lo spostamento, e la sua posizione finale lo fa espandere fino al 75% della viewport totale, l'impact fraction sarà 0.75.
- Distance Fraction: La distanza maggiore percorsa da qualsiasi elemento instabile nella viewport (orizzontalmente o verticalmente) divisa per la dimensione maggiore della viewport stessa (larghezza o altezza).
CLS = Impact Fraction × Distance Fraction
Un punteggio CLS di 0 significa nessuna instabilità visiva. Più il punteggio aumenta, maggiore è il layout shift. È una metrica cumulativa, il che significa che tutti i layout shift inattesi che si verificano durante la vita di una pagina vengono sommati fino a formare il punteggio finale.
Soglie CLS e il concetto di "session windows"
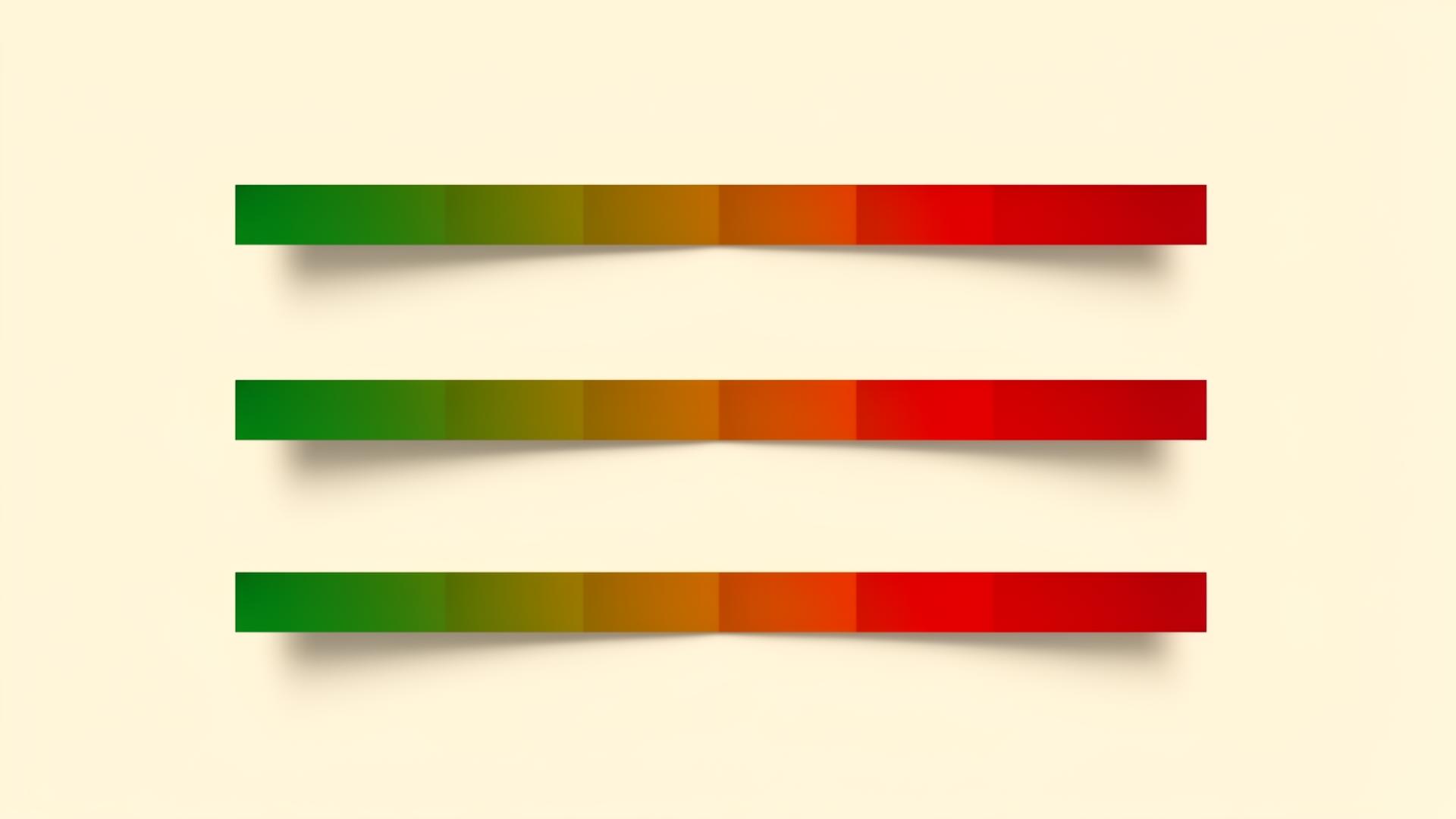
Le soglie stabilite da Google per il CLS sono:
- Buono: CLS inferiore a 0.1
- Migliorabile: CLS tra 0.1 e 0.25
- Insufficiente: CLS superiore a 0.25
Anche per il CLS, il 75° percentile è il riferimento. Raggiungere un punteggio inferiore a 0.1 per il 75% degli utenti è l'obiettivo.
Un aspetto importante da comprendere è il concetto di "session windows". Inizialmente, il CLS sommava indiscriminatamente tutti gli spostamenti di layout. Tuttavia, in contesti di lunga durata della pagina (es. single-page applications o utenti che rimangono su una pagina per molto tempo), questo poteva portare a punteggi CLS artificialmente alti. Per risolvere ciò, Google ha introdotto il concetto di "session windows": il CLS viene calcolato all'interno di "finestre" (sessioni) continue di layout shift. Una session window termina dopo 5 secondi di inattività (nessun layout shift) o se il totale cumulativo dei shift all'interno di una finestra supera 1 secondo. Il punteggio finale di CLS per una pagina è il punteggio massimo di una singola session window. Questo rende la metrica più fedele all'esperienza utente, concentrandosi sui cluster di instabilità.
Cause comuni di cambiamenti di layout inaspettati
Il CLS alto è spesso causato da una gestione non ottimale di risorse asincrone o da un'errata allocazione dello spazio. Ecco le cause più frequenti:
- Immagini senza dimensioni esplicite: Se un'immagine viene caricata senza specificare
widtheheightnell'HTML o via CSS, il browser non può riservare lo spazio corretto. Quando l'immagine viene finalmente scaricata e renderizzata, il suo spazio viene allocato, spingendo verso il basso o di lato il contenuto sottostante. Questo è probabilmente la causa più comune di CLS. - Annunci, embed e iframe: Contenuti di terze parti come annunci pubblicitari, widget di social media o video embedded spesso si caricano in modo asincrono. Se il loro contenitore non ha una dimensione predefinita o non riserva spazio, possono causare spostamenti significativi quando vengono iniettati nella pagina.
- Web Font che causano FOIT/FOUT:
- Flash of Invisible Text (FOIT): Il browser nasconde il testo finché il font web non è completamente caricato. Quando il font appare, il testo può richiedere uno spazio diverso, causando uno shift.
- Flash of Unstyled Text (FOUT): Il browser mostra il testo con un font di sistema (fallback) e, una volta caricato il font web, lo sostituisce. Se il font web ha metriche diverse (altezza riga, larghezza caratteri), causerà uno shift.
- Contenuto iniettato dinamicamente:
- Banner di consenso per i cookie: Molti siti mostrano un banner di consenso per i cookie nella parte superiore dello schermo. Se questo banner appare dopo che il contenuto principale è già stato renderizzato, sposta l'intera pagina verso il basso.
- Notifiche, promozioni: Popup o barre di notifica che compaiono in alto o in basso dopo il caricamento iniziale.
- JavaScript che modifica il DOM: Script che aggiungono o rimuovono elementi, o che modificano le dimensioni di elementi esistenti senza preallocare spazio.
- Animazioni basate su proprietà CSS che influenzano il layout: Animazioni che modificano proprietà come
width,height,top,left, omarginpossono contribuire al CLS se non gestite correttamente. È preferibile usaretransformoopacityper le animazioni, in quanto non influenzano il layout.
Strategie specifiche per ridurre il CLS
L'obiettivo principale è garantire che il browser possa riservare lo spazio corretto per tutti gli elementi prima che vengano renderizzati o che il loro contenuto venga caricato.
- Specificare dimensioni per immagini e video:
- Utilizza gli attributi
widtheheightnell'elemento<img>e<video>. Anche con immagini responsive (srcset), è fondamentale fornire le dimensioni di base che mantengono l'aspect ratio. - In CSS, puoi combinare questo con
max-width: 100%; height: auto;per la responsività, mentre il browser usa gli attributi width/height per calcolare l'aspect ratio e riservare lo spazio. Un'alternativa moderna è la proprietà CSSaspect-ratio.
- Utilizza gli attributi
- Preallocare spazio per annunci e iframe:
- Dimensioni fisse: Se conosci le dimensioni, preallocale con CSS (
min-height,min-width) o gli attributiwidtheheightsull'iframe. - Fallback per dimensioni variabili: Se gli slot pubblicitari possono variare dimensione, riserva lo spazio per la dimensione più grande possibile oppure crea un fallback con un segnaposto che occupi lo spazio minimo fino al caricamento dell'annuncio.
- Non posizionare annunci above-the-fold: Se possibile, evita di posizionare annunci o elementi dinamici sopra il contenuto principale.
- Dimensioni fisse: Se conosci le dimensioni, preallocale con CSS (
- Gestire i Web Font:
font-display: optionaloswap:font-display: swap;mostra immediatamente il testo con un font di fallback e poi lo scambia con il font web una volta caricato. Potrebbe causare un piccolo shift se le metriche sono diverse.font-display: optional;offre un approccio più aggressivo: usa il font di fallback per un brevissimo periodo. Se il font web non si carica subito, il browser continua a usare il font di fallback, evitando shift.
- Preload dei font: Precarica i font web critici per renderli disponibili il più presto possibile.
size-adjust,ascent-override,descent-overrideper font-face: Queste proprietà CSS consentono di allineare meglio le metriche del font web con quelle del font di fallback, riducendo lo shift quando il font viene scambiato.
- Evitare l'inserimento dinamico di contenuto:
- Riserva spazio: Se devi mostrare un banner cookie o una notifica, prealloca lo spazio per esso con CSS (es. un
<div>vuoto conmin-height) prima che venga popolato. - Posizionamento: Posiziona elementi che potrebbero causare shift (es. banner cookie) in aree che non influiscono gli elementi visibili chiave, ad esempio in un overlay fisso o al fondo della pagina.
- Sticky vs. Static: Usa posizionamento
stickyofixedper elementi che non devono spingere il contenuto o avrebbero altrimenti alterato il layout.
- Riserva spazio: Se devi mostrare un banner cookie o una notifica, prealloca lo spazio per esso con CSS (es. un
- Manipolazioni DOM:
- Evita di modificare il DOM o di iniettare nuovo contenuto sopra elementi esistenti dopo il caricamento iniziale, a meno che non sia in risposta a un'interazione utente esplicita.
- Se devi aggiornare l'UI, fallo in modo che non alteri le posizioni o le dimensioni di altri elementi nella viewport.
- Usa le proprietà CSS
transformeopacityper le animazioni: Queste proprietà non causano ricalcoli di layout e, di conseguenza, non generano CLS. Evita animarewidth,height,margin,padding,top,leftecc. - Attributo
containCSS: La proprietà CSScontain(e i suoi valori comelayout,paint,size) può aiutare il browser a isolare l'impatto delle modifiche al DOM a sottostrutture specifiche, contenendo i layout shift all'interno di un componente.
In sintesi, la chiave per un buon punteggio CLS è la prevedibilità. Il browser dovrebbe essere in grado di prevedere lo spazio che ogni elemento occuperà sulla pagina, prima che venga renderizzato, per evitare che i contenuti "saltino" inaspettatamente.
Metriche di Supporto per una Diagnosi Approfondita
Oltre ai tre Core Web Vitals (LCP, INP, CLS), esistono diverse altre metriche di performance che, pur non essendo direttamente fattori di ranking, sono estremamente utili per diagnosticare i problemi e comprendere il comportamento complessivo della pagina. Queste metriche vengono spesso visualizzate in Lighthouse e Chrome DevTools e forniscono un contesto importante per capire il "perché" dietro i punteggi dei Core Web Vitals.
TTFB (Time to First Byte): La reattività del server
- Definizione: Il Time to First Byte (TTFB) misura quanto tempo impiega il browser a ricevere il primo byte di risposta dal server web dopo che è stata effettuata una richiesta HTTP. In pratica, è il tempo che il server impiega per elaborare la richiesta e iniziare a inviare la risposta.
- Soglia consigliata: Meno di 800 millisecondi.
- Perché è importante: Un TTFB basso è il punto di partenza per una pagina veloce. Se il server è lento a rispondere, tutte le altre metriche saranno penalizzate, in particolare l'LCP. Il TTFB include la latenza di rete, il tempo di query DNS, il tempo di connessione, la negoziazione SSL e il tempo di elaborazione del server.
- Cause di TTFB elevato:
- Problemi di hosting (server sovraccarico, risorse insufficienti).
- Logica di backend inefficiente (query al database complesse, elaborazioni PHP/Node.js lunghe).
- Connessioni di rete lente tra l'utente e il server.
- Mancanza di caching server-side.
- Ottimizzazione: Migliorare l'hosting, implementare CDN, ottimizzare il codice backend, usare caching robusto (Varnish, Redis, Nginx FastCGI).
FCP (First Contentful Paint): Il primo segnale visivo
- Definizione: Il First Contentful Paint (FCP) misura il tempo dal momento in cui la pagina inizia a caricarsi fino a quando qualsiasi parte del contenuto della pagina è renderizzata sullo schermo. Questo può essere del testo, un'immagine (anche solo l'immagine di sfondo di un div), un SVG non bianco o un elemento canvas. È il primo punto in cui l'utente vede qualcosa di significativo accadere sulla pagina.
- Soglia consigliata: Meno di 1.8 secondi per essere "buono".
- Perché è importante: FCP dà all'utente il primo feedback visivo che la pagina sta caricando. Un FCP rapido riduce la percezione di una schermata bianca prolungata. È correlato all'LCP, ma LCP si concentra sul "contenuto principale", mentre FCP è il "primo contenuto" di qualsiasi tipo.
- Cause di FCP elevato:
- TTFB elevato.
- Risorse che bloccano il rendering (CSS, JS) che ritardano la prima pittura.
- Font web che ritardano la visualizzazione del testo.
- Ottimizzazione: Simile all'LCP, con enfasi sulla minimizzazione delle risorse render-blocking e del TTFB.
TBT (Total Blocking Time): Analizzare il blocco del thread principale
- Definizione: Il Total Blocking Time (TBT) misura il tempo totale in cui il thread principale del browser è stato bloccato per un tempo sufficientemente lungo da impedire la risposta all'input dell'utente. Si concentra sul periodo tra il First Contentful Paint (FCP) e il Time To Interactive (TTI). Specifically, misura la somma dei "lunghe task" (long tasks): qualsiasi task della durata superiore a 50 ms. Solo la porzione di tempo in eccesso rispetto ai 50 ms viene conteggiata nel TBT. Ad esempio, un task di 100 ms contribuisce con 50 ms al TBT.
- Soglia consigliata (solo lab): Meno di 200 millisecondi.
- Perché è importante: TBT è una metrica di laboratorio (non basata su field data) che è fortemente correlata all'INP. Un TBT elevato indica che il thread principale è spesso bloccato, il che impedisce un'interattività rapida. È un eccellente indicatore per diagnosticare problemi che influenzano la reattività.
- Cause di TBT elevato:
- Eccessivo JavaScript che viene eseguito sul thread principale.
- Operazioni DOM complesse e costose.
- Script di terze parti non ottimizzati.
- Ottimizzazione: Code splitting, lazy loading di JS, utilizzo di Web Workers, ottimizzazione degli script di terze parti, yielding al thread principale.
Speed Index e TTI (Time to Interactive): Altri indicatori utili
- Speed Index:
- Definizione: Misura la velocità con cui il contenuto è visibilmente popolato nella viewport durante il caricamento della pagina. È un valore che rappresenta il tempo medio in cui i pixel visibili vengono dipinti sullo schermo.
- Soglia consigliata: Meno di 3.4 secondi per essere "buono".
- Perché è importante: Speed Index è una metrica di laboratorio che cattura la velocità percepita del caricamento visivo. Un punteggio basso indica che la pagina si riempie visivamente rapidamente.
- TTI (Time to Interactive):
- Definizione: Misura il tempo necessario affinché una pagina diventi completamente interattiva. Una pagina è considerata interattiva quando il contenuto visibile è stato renderizzato, i gestori di eventi sono stati registrati per la maggior parte degli elementi dell'interfaccia utente visibili e la pagina risponde alle interazioni dell'utente entro 50 millisecondi.
- Soglia consigliata (deprecato lato Lighthouse 10): Meno di 3.8 secondi per essere "buono".
- Perché è importante: TTI è stata una metrica chiave per misurare l'interattività ma, come indicato, è stata in qualche modo deprecata in favore di INP, ritenuto più rappresentativo delle reali interazioni. Rimane utile per contesti specifici, ma l'attenzione di Google si è spostata su INP.
In sintesi, mentre LCP, INP e CLS sono le metriche "core" che Google usa per il ranking, metriche come TTFB, FCP e TBT sono strumenti diagnostici essenziali. Comprendendo e monitorando queste metriche di supporto, gli sviluppatori possono identificare più facilmente la radice dei problemi di performance e implementare soluzioni mirate per i Core Web Vitals.
Strumenti per Misurare e Analizzare i Core Web Vitals
Per ottimizzare i Core Web Vitals, è indispensabile poterli misurare in modo accurato e comprendere le cause alla base di eventuali scostamenti dalle soglie desiderate. Fortunatamente, Google e la community hanno fornito un ricco ecosistema di strumenti, sia per i dati di laboratorio (lab data) che per i dati sul campo (field data).
Chrome DevTools: La scheda Performance
Tipo di dati: Lab Data
Chrome DevTools, integrato in ogni browser Chrome, è lo strumento più potente e granulare per analizzare le prestazioni a livello di codice. In particolare, la scheda "Performance" (o "Prestazioni"):
- Registrazione delle attività: Consente di registrare una sessione di caricamento o interazione con la pagina e visualizzare un timeline dettagliato di tutti gli eventi che accadono sul thread principale, GPU, Network e altro.
- Identificazione di Long Tasks: Mostra chiaramente i "Long Task" (task che durano più di 50ms) che sono cruciali per l'ottimizzazione dell'INP. È possibile vedere la causa esatta del blocco del thread principale.
- Visualizzazione degli spostamenti di layout: La sezione "Experience" all'interno della registrazione visualizza i layout shift, permettendo di identificare gli elementi che si spostano e il loro impatto.
- Analisi del rendering: Mostra quando avvengono i "paints" (pitture) e i "layouts", utile per capire il presentation delay all'interno dell'INP.
- Albero DOM e selezione degli elementi: Cliccando sugli eventi nella timeline, puoi vedere l'elemento specifico coinvolto in LCP, CLS, ecc., e navigare al suo codice.
Come usarla: Apri DevTools (F12), vai alla scheda Performance, clicca sul pulsante di registrazione (cerchio rosso) o premi Ctrl+E, ricarica la pagina e/o interagisci con essa, poi ferma la registrazione. Analizza il waterfall, gli eventi e i grafici per identificare i colli di bottiglia e gli elementi problematici.
Lighthouse e PageSpeed Insights: Auditing on-demand
Tipo di dati: PageSpeed Insights (PSI) combina Lab Data (tramite Lighthouse) e Field Data (tramite CrUX). Lighthouse fornisce solo Lab Data.
- Lighthouse: È uno strumento open-source automatizzato di Google per migliorare la qualità delle pagine web. Puoi eseguirlo da Chrome DevTools (scheda "Lighthouse"), come estensione del browser, come CLI tool (
npm install -g lighthouse) o come un modulo Node.js. Genera report approfonditi su performance, accessibilità, SEO, best practices e PWA. - PageSpeed Insights (PSI): È uno strumento web di Google (pagespeed.web.dev) che, dato un URL, restituisce un report completo.
- Field Data: Mostra i dati sui Core Web Vitals raccolti dal Chrome User Experience Report (CrUX) per quell'URL negli ultimi 28 giorni (se disponibili). Questi sono i dati che Google utilizza per il ranking.
- Lab Data: Esegue un audit Lighthouse in tempo reale sul server di Google, fornendo un punteggio di performance e suggerimenti diagnostici specifici per risolvere i problemi identificati.
Come usarli: Inserisci l'URL in PSI per avere una panoramica complessiva con dati reali e simulati. Usa Lighthouse in DevTools per testare rapidamente i cambiamenti in locale o su staging, con la possibilità di emulare diversi dispositivi e connessioni. I suggerimenti di Lighthouse sono essenziali per capire cosa fare concretamente.
Google Search Console: La sezione "Esperienza"
Tipo di dati: Field Data (CrUX)
La sezione "Esperienza" di Google Search Console è vitale per monitorare le prestazioni dei Core Web Vitals del tuo intero sito, basandosi sui dati reali del CrUX.
- Rapporto Core Web Vitals: Mostra quali pagine (o gruppi di pagine con lo stesso template) superano, migliorano o falliscono le soglie dei Core Web Vitals, sia per desktop che per mobile.
- Rapporto Segnali web essenziali: Fornisce un riepilogo grafico dell'andamento delle metriche nel tempo.
- Identificazione di problemi a livello di sito: Permette di identificare rapidamente le pagine che necessitano di attenzione. Cliccando sui dettagli, è possibile vedere quali problematiche specifiche (LCP, INP, CLS) affliggono le pagine.
Come usarla: Controlla regolarmente Search Console per avere una visione d'insieme delle prestazioni del tuo sito nel tempo. È il punto di partenza per identificare le aree problematiche che necessitano di un'indagine più approfondita con strumenti di laboratorio.
Chrome UX Report (CrUX) e BigQuery: Dati reali su larga scala
Tipo di dati: Field Data
Il CrUX è la fonte dei dati reali di Google. Oltre a essere integrato in PSI e Search Console, i dati grezzi del CrUX sono disponibili in diverse forme:
- CrUX Dashboard in Looker Studio (ex Google Data Studio): Un modo semplice per esplorare i dati CrUX per qualsiasi dominio, senza scrivere query SQL. È utile per visualizzare le tendenze nel tempo.
- CrUX API: Permette di recuperare i dati CrUX programmaticamente per un URL o un'origine specifica.
- CrUX su BigQuery: Il dataset completo e anonimizzato del CrUX è disponibile pubblicamente su Google BigQuery. Offre una granularità e una flessibilità di analisi che nessun altro strumento può eguagliare. Puoi scrivere query SQL complesse per analizzare le prestazioni su ampi set di URL, segmentando per paese, tipo di connessione, dispositivo, ecc. Questa è la risorsa definitiva per chi ha bisogno di analisi avanzate e storiche.
Come usarlo: BigQuery è per analisi avanzate. La Dashboard in Looker Studio è un ottimo punto di partenza per chiunque voglia visualizzare rapidamente i dati CrUX per il proprio sito o per siti competitor.
Web Vitals Extension per Chrome: Monitoraggio in tempo reale
Tipo di dati: Field Data (basata su API web-vitals)
Questa estensione (disponibile sul Chrome Web Store) è uno strumento leggero ma estremamente utile per visualizzare i Core Web Vitals in tempo reale mentre navighi su qualsiasi pagina. Mostra i valori di LCP, INP e CLS direttamente nell'angolo superiore dello schermo.
- Feedback immediato: Ti dà un'idea istantanea delle performance di una pagina senza dover aprire DevTools o PSI.
- Simulazione di rete/CPU: Puoi configurare l'estensione per emulare condizioni di rete e CPU più lente, utile per testare come si comporta la pagina in scenari meno ideali.
Come usarla: Installala e lasciala attiva. Ti darà un feedback costante mentre navighi, aiutandoti a identificare a colpo d'occhio le pagine problematiche del tuo sito o quelle dei competitor.
web-vitals npm library: Monitoraggio programmatico
Tipo di dati: Field Data (Real User Monitoring - RUM)
La libreria JavaScript web-vitals di Google è un modo per raccogliere i Core Web Vitals direttamente dai tuoi utenti reali e inviarli a un servizio di analytics di tua scelta (Google Analytics, soluzioni di terze parti, o un endpoint backend personalizzato).
// Esempio di utilizzo della lib web-vitals
import { getLCP, getINP, getCLS } from 'web-vitals';
function sendToAnalytics(metric) {
const body = JSON.stringify(metric);
// Puoi inviarli a Google Analytics 4, a un tuo endpoint, ecc.
// Esempio per un endpoint personalizzato:
// navigator.sendBeacon('/analytics', body);
console.log(metric);
}
getLCP(sendToAnalytics);
getINP(sendToAnalytics);
getCLS(sendToAnalytics);Come usarla: Integra questa libreria nel tuo codice JavaScript. Ti permetterà di raccogliere dati RUM specifici per il tuo sito, monitorando le metriche per l'intera base utenti, non solo quelli inclusi nel CrUX, e potendo segmentare i dati in base a parametri personalizzati (es. tipo di utente, A/B testing). È essenziale per un monitoraggio continuo e personalizzato delle prestazioni.
L'utilizzo combinato di questi strumenti permette un approccio completo all'ottimizzazione: dalla rapida identificazione dei problemi a livello di sito con Search Console, alla diagnosi approfondita delle cause con Chrome DevTools e Lighthouse, fino al monitoraggio continuo con la libreria web-vitals e BigQuery per analisi di trend e segmentazione. Nessuno strumento è sufficiente da solo; la loro sinergia è la chiave del successo.
Workflow di Ottimizzazione Concreto: Dalla Diagnosi al Monitoring Continuo
L'ottimizzazione dei Core Web Vitals non è un'attività da svolgere una tantum, ma un processo continuo che richiede monitoraggio, analisi e iterazione. Un approccio metodico è essenziale per ottenere risultati duraturi. Ecco un workflow pratico e concreto.
Fase 1: Audit e identificazione dei problemi
- Inizia con Google Search Console (Field Data):
- Controlla il rapporto "Core Web Vitals" sotto "Esperienza".
- Identifica quali metriche (LCP, INP, CLS) sono in stato "Insufficiente" o "Migliorabile" e su quali categorie di pagine (desktop/mobile).
- Concentrati sulle pagine con il maggior volume di traffico o quelle strategicamente più importanti (es. home page, schede prodotto, landing page). Se GSC raggruppa le pagine per URL pattern, identifica il template problematico.
- Approfondisci con PageSpeed Insights (PSI - Field & Lab Data):
- Prendi un URL rappresentativo da ogni categoria problematica individuata in Search Console.
- Inserisci l'URL in PageSpeed Insights.
- Analizza sia i "Dati del campo" (CrUX) per confermare il problema, sia i "Dati di laboratorio" (Lighthouse) per ottenere suggerimenti diagnostici.
- Presta particolare attenzione alla sezione "Diagnostica" e ai suggerimenti sotto "Opportunità" e "Diagnostici" che Lighthouse fornisce per LCP, INP e CLS.
- Analisi dettagliata con Chrome DevTools (Lab Data):
- Apri la pagina problematica nel browser Chrome.
- Apri DevTools (F12) e vai alla scheda "Performance".
- Registra un caricamento della pagina e/o interazioni specifiche che sospetti causino problemi.
- Per LCP: Cerca il momento in cui l'LCP viene misurato sulla timeline e analizza la catena di eventi che lo precedono (TTFB, caricamento di risorse, script che bloccano).
- Per INP: Identifica i "Long Task" (blocchi rossi sulla timeline del thread principale) e gli eventi che avvengono durante le interazioni. Analizza il "Input Delay", "Processing Time" e "Presentation Delay".
- Per CLS: Cerca gli "Layout Shift" sulla timeline e identifica gli eventi e gli elementi che li hanno causati.
- La scheda "Network" è utile per analizzare i tempi di caricamento delle risorse, il tempo di blocco e le priorità.
Fase 2: Quick Wins e prioritizzazione
- Elenca tutti i problemi identificati: Trasforma i suggerimenti degli strumenti (PSI, DevTools) in una lista di azioni concrete.
- Identifica i "Quick Wins": Sono modifiche che richiedono poco sforzo ma che possono avere un impatto significativo. Esempi:
- Aggiungere
width/heightad immagini senza dimensioni. - Caricare script JS con
deferoasync. - Ottimizzare un'immagine LCP non compressa.
- Abilitare la compressione GZIP/Brotli sul server.
- Aggiungere
- Prioritizza in base all'impatto e allo sforzo:
- Concentrati sulle metriche in stato "Insufficiente" prima delle "Migliorabile".
- Classifica le azioni in base al loro potenziale impatto sul punteggio e alla complessità/tempo richiesto per l'implementazione.
- Inizia con le azioni ad alto impatto e basso sforzo.
Fase 3: Implementazione e testing
- Implementa le modifiche: Applica le ottimizzazioni identificate, possibilmente in un ambiente di staging o di sviluppo.
- Test in ambiente di laboratorio (DevTools, Lighthouse):
- Dopo ogni gruppo di modifiche, esegui nuovamente Lighthouse dalla scheda in DevTools sulla pagina modificata.
- Verifica che i punteggi siano migliorati e che i suggerimenti diagnostici siano stati risolti.
- Simula diverse condizioni (connessioni lente, dispositivi mobili) per assicurarti che le ottimizzazioni siano robuste.
- Rollout in produzione con cautela: Una volta soddisfatto dei risultati in laboratorio, distribuisci le modifiche in produzione. Il rollout incrementale può aiutare a mitigare i rischi.
Fase 4: Monitoring continuo e manutenzione
- Monitoraggio dei Field Data (Search Console, web-vitals lib):
- Osserva i rapporti Core Web Vitals in Google Search Console. I dati del CrUX si aggiornano ogni 28 giorni, quindi ci vorrà un po' di tempo per vedere l'impatto delle tue modifiche. Google invia notifiche in caso di miglioramenti (o peggioramenti).
- Se hai implementato la libreria
web-vitals, monitora i dati RUM in tempo reale nel tuo sistema di analytics per feedback più immediato e segmentato.
- Revisioni periodiche: Le prestazioni di un sito non sono statiche. Nuovi contenuti, plugin, terze parti o aggiornamenti possono introdurre regolarmente nuovi problemi. Pianifica audit di performance regolari.
- Rimani aggiornato: Google aggiorna e raffina le metriche e le linee guida. Segui blog come web.dev/vitals per rimanere informato sulle ultime novità, come l'introduzione di INP.
- Analisi della concorrenza: Utilizza PageSpeed Insights per analizzare i siti dei tuoi concorrenti e capire come si posizionano rispetto a te in termini di Core Web Vitals. Questo può offrire ispirazione e identificare ulteriori opportunità di miglioramento.
Questo workflow garantisce che tu stia costantemente ottimizzando il tuo sito in un ciclo virtuoso di miglioramento, basato su dati reali e su analisi tecniche approfondite. L'obiettivo non è raggiungere un punteggio perfetto una volta e poi dimenticarsene, ma mantenere costantemente un'esperienza utente di alta qualità.
Errori Comuni e Miti da Sfatare sui Core Web Vitals
Intorno ai Core Web Vitals sono sorti diversi fraintendimenti e "best practice" fuorvianti. Chiarire questi punti è fondamentale per un'ottimizzazione efficace.
Mito 1: Un punteggio Lighthouse di 100 garantisce Core Web Vitals ottimi.
Falso. Un punteggio Lighthouse di 100 in un ambiente di laboratorio (lab data) è certamente un ottimo punto di partenza, ma non garantisce automaticamente un passaggio nei Core Web Vitals basato sui field data. Il motivo principale è la differenza tra lab e field data discussa in precedenza. Lighthouse testa la pagina in un ambiente controllato e simulato. Gli utenti reali del tuo sito, invece, navigano con una varietà di dispositivi, connessioni di rete (spesso peggiori di quelle simulate), in diverse posizioni geografiche e con altri processi in esecuzione in background. Se il 75° percentile dei tuoi utenti reali vive un'esperienza lenta a causa di queste variabili, i tuoi Core Web Vitals reali saranno "Insufficienti" anche con un 100 in Lighthouse. Lighthouse è uno strumento diagnostico, Search Console e CrUX sono gli strumenti di verifica.
Errore 1: Concentrarsi solo sulla velocità di caricamento iniziale.
Parzialmente vero, ma incompleto. Mentre LCP è certamente legato alla velocità di caricamento iniziale, INP e CLS non lo sono esclusivamente. INP misura la reattività durante l'intera vita della pagina, e CLS può verificarsi molto dopo il caricamento iniziale a causa di script di terze parti, annunci o contenuti dinamici. Concentrarsi solo sul fast-load e ignorare le interazioni successive o gli spostamenti di layout è un errore comune che può portare a fallire gli altri Core Web Vitals.
Mito 2: Basta installare un plugin o un tema X per risolvere i problemi di Core Web Vitals.
Falso. Non esiste una soluzione "magica" universale. I plugin di caching e ottimizzazione possono aiutare, ma non risolveranno i problemi strutturali di un tema mal codificato, di un hosting scadente o di JavaScript di terze parti ingombrante. Molti plugin promettono ottimizzazione, ma spesso non basta. In alcuni casi, plugin multipli possono entrare in conflitto, peggiorando le performance. Ogni sito è unico e richiede un'analisi specifica e un intervento mirato.
Errore 2: Lazy loading indiscriminato, anche sull'elemento LCP.
Errore grave. Il lazy loading (loading="lazy") è una tecnica eccellente per posticipare il caricamento di immagini e iframe al di sotto della viewport. Tuttavia, applicarlo all'immagine o all'elemento di testo che costituisce il Largest Contentful Paint (LCP) è controproducente. Il browser darà bassa priorità al caricamento di quell'elemento, ritardandone la comparsa e penalizzando pesantemente l'LCP. Il contenuto above-the-fold critico deve essere caricato con la massima priorità.
Mito 3: I Core Web Vitals sono solo per i grandi siti o e-commerce.
Falso. Indipendentemente dalle dimensioni o dal tipo di sito (blog, portfolio, sito aziendale), i Core Web Vitals sono un fattore di ranking e un segnale di qualità dell'esperienza utente. Anche un piccolo blog può trarre beneficio da un'esperienza utente fluida e reattiva, migliorando la fidelizzazione dei lettori e la visibilità sui motori di ricerca. Anzi, per i siti più piccoli e con meno budget marketing, l'ottimizzazione SEO (inclusi i CWV) può essere ancora più critica per acquisire traffico organico.
Errore 3: Ignorare le terze parti.
Errore comune. Script di terze parti (Google Analytics, tag manager, annunci, widget social, chatbot) spesso contribuiscono in modo significativo ai problemi di Core Web Vitals. Possono introdurre Long Tasks, bloccare il thread principale, causare layout shift o rallentare l'LCP. Non è sufficiente ottimizzare solo il proprio codice; è cruciale monitorare e, se possibile, ottimizzare o deferire il caricamento di tutte le risorse di terze parti. Usare l'attributo defer o async sugli script di terze parti è un buon primo passo.
Mito 4: Un lento TTFB è sempre la colpa dell'hosting.
Falso. Sebbene l'hosting abbia un impatto significativo, un TTFB elevato può essere causato anche da un backend inefficiente (logica di business complessa, query database non ottimizzate), da una scarsa configurazione del caching lato server, o anche da una latenza di rete elevata tra il server e l'utente a causa di una CDN non configurata correttamente o non utilizzata. È necessario diagnosticare la causa esatta prima di puntare il dito solo sull'hosting.
Errore 4: Non testare su dispositivi reali e connessioni lente.
Errore fondamentale. Testare solo su una connessione fibra e un computer potente non fornisce una rappresentazione accurata dell'esperienza della maggior parte degli utenti. È cruciale testare su dispositivi mobili (anche Android di fascia media), con connessioni 3G/4G simulate (utilizzando le opzioni di throttling di rete in Chrome DevTools o l'estensione Web Vitals) per comprendere come il tuo sito si comporta per un pubblico più ampio. Le condizioni di rete e CPU peggiori sono quelle dove i problemi ai Core Web Vitals vengono più facilmente alla luce.
Mito 5: I Web Vitals sono una gara a chi ce l'ha più veloce, e una volta raggiunte le soglie è finita.
Falso. L'obiettivo non è un record di velocità fine a sé stesso, ma un'esperienza utente di qualità. E le aspettative degli utenti evolvono. Raggiungere le soglie è il minimo indispensabile per non essere penalizzati e per offrire un'esperienza decente. Ma il lavoro non finisce mai. Il web si evolve, i browser cambiano, nuove tecnologie emergono, e le prestazioni del tuo sito possono degradare con l'aggiunta di nuove funzionalità o contenuti. Il monitoraggio continuo e l'iterazione costante sono la chiave per mantenere un vantaggio competitivo e fornire un'esperienza superiore nel lungo periodo.
Caso Studio 1604lab: Hyvä Magento 2 e Core Web Vitals Eccellenti
Nel contesto dell'ottimizzazione per i Core Web Vitals, è fondamentale dimostrare che gli sforzi tecnici si traducono in risultati reali. Presso 1604lab, abbiamo un impegno costante verso l'eccellenza delle performance, in particolare nell'ecosistema Magento 2. Un esempio lampante di questo approccio è l'adozione strategica del nuovo frontend Hyvä Themes per Magento 2.
Hyvä Themes è emerso come una soluzione rivoluzionaria per Magento, un framework tradizionalmente noto per la sua complessità e, di conseguenza, per le sue sfide in termini di performance frontend. La filosofia di Hyvä si basa sulla riduzione drastica del JavaScript e del CSS caricato, abbracciando un approccio "vanilla" e concentrandosi sulla semplicità e l'efficienza. Questo tipo di architettura si allinea perfettamente con i principi di ottimizzazione dei Core Web Vitals.
Abbiamo avuto il piacere e la responsabilità di implementare Hyvä Themes per diversi nostri clienti, ottenendo risultati notevoli. In particolare, per tre store e-commerce basati su Magento 2, siamo riusciti a portare tutte le pagine in "zona verde" per i Core Web Vitals di Google. Questo significa che almeno il 75% degli utenti reali di questi siti web sperimenta:
- LCP (Largest Contentful Paint) inferiore a 2.5 secondi.
- INP (Interaction to Next Paint) inferiore a 200 millisecondi.
- CLS (Cumulative Layout Shift) inferiore a 0.1.
Raggiungere questi parametri su piattaforme e-commerce complesse come Magento 2, spesso ricche di funzionalità, integrazioni di terze parti e cataloghi estesi, è un traguardo significativo. È la prova che, con la giusta architettura (come Hyvä), un'attenta strategia di sviluppo e un focus costante sulle performance, è possibile superare le sfide intrinseche della piattaforma e offrire un'esperienza utente di prim'ordine.
Questo successo non è arrivato per caso. È il risultato di un profondo lavoro che comprende:
- Minimizzazione del JavaScript e CSS: L'architettura snella di Hyvä ha permesso di ridurre drasticamente i bundle di JavaScript e CSS, liberando il thread principale e accelerando il rendering.
- Ottimizzazione delle immagini: Implementazione di formati moderni (WebP), lazy loading selettivo e dimensionamento responsivo di tutte le immagini.
- Gestione efficiente delle terze parti: Caricamento differito e asincrono di script esterni per minimizzare l'impatto su LCP e INP.
- Caching aggressivo lato server e client: Strategie avanzate di caching per ridurre il TTFB e servire le pagine più velocemente.
- Ottimizzazione del server e del database: Assicurarsi che l'infrastruttura sottostante sia performante e reattiva.
- Attenzione al CLS: Preallocazione dello spazio per tutti gli elementi dinamici e gestione accurata dei web font per eliminare gli shift inaspettati.
Il risultato concreto di questi interventi è un aumento del traffico organico, una riduzione del tasso di rimbalzo, un miglioramento dei tassi di conversione e, in generale, clienti più soddisfatti grazie a un'esperienza di navigazione fluida e reattiva. Questa testimonianza riflette la nostra capacità di trasformare le sfide tecniche in opportunità di crescita reale per i nostri partner.
Per approfondire ulteriormente i nostri risultati e le metodologie utilizzate nel contesto Hyvä Magento 2, ti invitiamo a consultare il nostro articolo dedicato sui case study di performance:
Hyvä Magento 2 Frontend Performance: Casi Studio 1604lab
Questo caso studio dimostra che l'investimento nei Core Web Vitals, quando eseguito con competenza e utilizzando le giuste tecnologie, porta a un ROI tangibile e duraturo per il business.
FAQ: Domande Frequenti sui Core Web Vitals
Quanto sono importanti i Core Web Vitals per la SEO?
I Core Web Vitals sono un fattore di ranking diretto per Google dal 2021 (Page Experience Update), ma la loro importanza è spesso fraintesa. Non sono il fattore di ranking più importante in assoluto; il contenuto di alta qualità, pertinente e autorevole rimane primario. Tuttavia, in situazioni di parità di qualità del contenuto, i Core Web Vitals possono fare la differenza. Per Google, una migliore esperienza utente si traduce in un miglior posizionamento. Inoltre, impattano indirettamente la SEO migliorando i segnali di coinvolgimento (riduzione del bounce rate, aumento del tempo sulla pagina) e, poiché sono basati sull'algoritmo mobile-first, sono cruciali per la visibilità su dispositivi mobili. Quindi, sono importanti come parte di una strategia SEO olistica, non come unica soluzione.
Posso ignorare i Core Web Vitals se ho un sito piccolo?
Assolutamente no. Indipendentemente dalle dimensioni del sito, i Core Web Vitals influenzano l'esperienza utente e il potenziale ranking. Anche un piccolo blog o un sito vetrina beneficiano di un caricamento veloce, di un'interattività fluida e di un layout stabile. Anzi, per i siti più piccoli, che spesso non hanno il "brand authority" dei grandi player, ottimizzare ogni aspetto della SEO, inclusi i CWV, può essere ancora più critico per distinguersi e acquisire traffico organico.
È possibile raggiungere un punteggio perfetto su PageSpeed Insights (100/100)?
Raggiungere un 100/100 su PageSpeed Insights (per i lab data) è tecnicamente possibile, ma non è sempre l'obiettivo più realistico o economicamente vantaggioso. Spesso richiede compromessi significativi (es. rimuovere alcune funzionalità, semplificare il design, eliminare terze parti) che potrebbero non essere giustificati dal ritorno sull'investimento aggiuntivo. L'obiettivo dovrebbe essere piuttosto quello di assicurarsi che tutti i Core Web Vitals siano in "zona verde" (good) per i field data, che è ciò che conta per Google e per l'esperienza reale degli utenti. I punteggi alti in Lighthouse sono un indicatore di buona ottimizzazione, ma non una fine a sé stante.
Quanto tempo ci vuole per vedere i miglioramenti dopo l'ottimizzazione?
I dati di laboratorio (Lighthouse, DevTools) mostreranno miglioramenti quasi istantaneamente. Tuttavia, per i field data (Google Search Console, CrUX) ci vuole più tempo. Google aggrega i dati su un periodo di 28 giorni. Ciò significa che dopo aver implementato le modifiche, dovrai attendere almeno quel periodo per vedere l'impatto completo nei rapporti di Search Console. È comune vedere un miglioramento graduale nel corso di alcune settimane man mano che più utenti reali sperimentano la versione ottimizzata del tuo sito.
I web font influenzano LCP e CLS? Come?
Sì, i web font possono avere un impatto significativo sia sull'LCP che sul CLS.
- LCP: Se l'elemento più grande nella viewport è un blocco di testo e il font web non è ancora caricato, il browser potrebbe ritardare la visualizzazione del testo (Flash of Invisible Text - FOIT) o mostrarlo con un font di fallback per poi cambiarlo (Flash of Unstyled Text - FOUT). Entrambi questi scenari possono ritardare il momento in cui l'LCP viene conteggiato.
- CLS: Quando il font web finalmente si carica e sostituisce un font di sistema (fallback), le metriche del font (altezza riga, spaziatura dei caratteri, larghezza) possono essere diverse. Questo cambio improvviso del font può causare uno spostamento del layout del testo e degli elementi circostanti se lo spazio occupato cambia, contribuendo al CLS.
<link rel="preload" as="font" ...>), usare font-display: swap o optional nel CSS, e tentare di abbinare le metriche dei font di fallback con quelle dei font web tramite le proprietà size-adjust, ascent-override, ecc.
Che ruolo hanno le CDN nell'ottimizzazione dei Core Web Vitals?
Le CDN (Content Delivery Network) giocano un ruolo cruciale, principalmente migliorando il TTFB e quindi indirettamente l'LCP. Funzionano distribuendo copie dei tuoi asset statici (immagini, CSS, JS) su server sparsi in tutto il mondo. Quando un utente richiede una risorsa, viene servita dal server CDN più vicino geograficamente. Questo riduce la latenza di rete e il tempo di caricamento, perché i dati devono percorrere meno distanza. Inoltre, molte CDN offrono funzionalità aggiuntive come la compressione automatica, l'ottimizzazione delle immagini (formati moderni, ridimensionamento) e il caching avanzato, che contribuiscono ulteriormente a migliorare le prestazioni generali e i Core Web Vitals.
Fonti Ufficiali e Risorse Utili
- web.dev/vitals: Introduzione ai Core Web Vitals
- web.dev/lcp: Ottimizzazione del Largest Contentful Paint
- web.dev/inp: Ottimizzazione dell'Interaction to Next Paint
- web.dev/cls: Ottimizzazione del Cumulative Layout Shift
- web.dev/ttfb: Ottimizzazione del Time to First Byte
- web.dev/fcp: Ottimizzazione del First Contentful Paint
- developers.google.com/search/docs/appearance/core-web-vitals: Core Web Vitals e Ricerca Google
- developer.chrome.com/docs/crux: Chrome User Experience Report
- github.com/GoogleChrome/web-vitals: Libreria JavaScript per la misurazione
- PageSpeed Insights: Strumento di analisi di Google
- Estensione Web Vitals per Chrome
Contattaci per l'ottimizzazione dei tuoi Core Web Vitals
L'ottimizzazione dei Core Web Vitals è un processo complesso che richiede competenze tecniche specifiche e un approccio strategico. Se il tuo sito fatica a raggiungere le soglie ottimali, o se desideri migliorare l'esperienza utente e la visibilità organica, il team di 1604lab è qui per aiutarti.
Con anni di esperienza nello sviluppo web e nell'ottimizzazione delle performance, specialmente su piattaforme complesse come Magento 2 (anche con l'innovativo frontend Hyvä Themes), possiamo analizzare il tuo sito, identificare i colli di bottiglia e implementare soluzioni mirate per portare i tuoi Core Web Vitals in "zona verde".
Non lasciare che prestazioni scadenti ostacolino il tuo successo online. Migliora la tua SEO, incrementa il tuo tasso di conversione e offri ai tuoi utenti un'esperienza di navigazione superiore.
Contattaci oggi stesso per una consulenza personalizzata:
Scopri di più sui nostri servizi di ottimizzazione performance, inclusi i servizi dedicati a Hyvä Themes: